DOM之访问

今天无意中看到一篇文章觉得可以很好的回顾一下关于DOM基础知识,故翻译了一下~原文链接是here
所有的起源都来源于document这个对象。这个对象提供了提供了很多方法来搜索和修改元素。
根元素:documentElement和body
DOM的根元素总是document.documentElement, 它是一个可以引用最开始的HTML标签的特殊属性。另一个起点的属性是document.body,它表示了BODY标签。
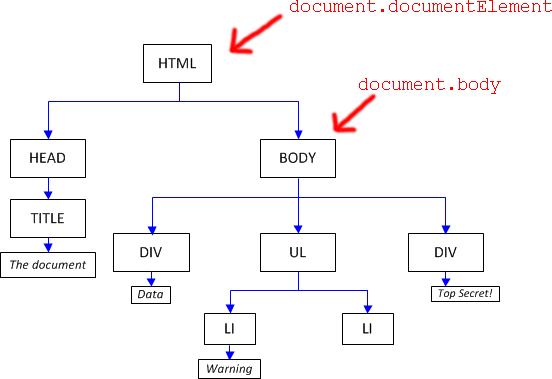
这两个进入点都是有效的,但是document.body可以为null,比如这种情况,在HEAD标签里试图访问body就会是null,因为此时还没有解析到body标签。
<!DOCTYPE HTML>
<html>
<head>
<script>
alert("Body from HEAD: "+document.body) // null
</script>
</head>
<body>
<div>The document</div>
<script>
// different browsers output different text here,
// because of different implementations of toString
alert("Body from inside body: " + document.body)
</script>
</body>
</html>
相反,document.documentElement总是可以被访问到的。还需要注意的是document.body不能是undefined。因为在DOM的世界里,没有这个元素或者这个元素找不到就总会被表示为null。在访问脚本执行时是访问不到还没有被渲染的元素的。
子元素
childNodes
一个元素拥有一个类数组属性childNodes指向自己的所有直接子元素们。所有的节点都会被引用起来,包括空白节点(处理IE<9).
<!DOCTYPE HTML>
<html>
<body>
<div>Allowed readers:</div>
<ul>
<li>Bob</li>
<li>Alice</li>
</ul>
<!-- a comment node -->
<script>
function go() {
var childNodes = document.body.childNodes
for(var i=0; i<childNodes.length; i++) {
alert(childNodes[i])
}
}
</script>
<button onclick="go()" style="width:100px">Go!</button>
</body>
</html>
注意SCRIPT节点也会被遍历出来。还有就是document.body.childNodes[1]是DIV,但是在IE<9的情况下,由于没有空白节点,所有document.body.childNodes是UL。
children
有时候我们只需要元素节点,而不需要其他类型的节点(比如text节点,注释节点等),此时使用children属性来访问再方便不过了。
<!DOCTYPE HTML>
<html>
<body>
<div>Allowed readers:</div>
<ul>
<li>Bob</li>
<li>Alice</li>
</ul>
<!-- a comment node -->
<script>
function go() {
var children = document.body.children
for(var i=0; i<children.length; i++) {
alert(children[i])
}
}
</script>
<button onclick="go()" style="width:100px">Go!</button>
</body>
</html>
注意IE<9的话,注释节点也会存在于children中。
Children links
只是得到节点的子元素还不足以方便的遍历DOM,所有我们还需要一些其他属性,例如siblings和parent等。
firstChild 和 lastChild
用来快速访问一个节点的第一个或者最后一个子元素
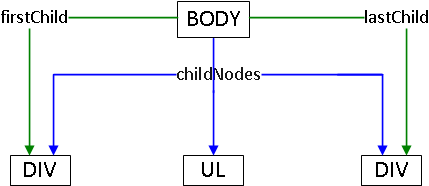
所以以下代码是相等的:
var body = document.body
alert(body.firstChild === body.childNodes[0])
alert(body.lastChild === body.childNodes[body.childNodes.length-1])
parentNode, previousSibling 和 nextSibling
- parentNode属性指向节点的父节点。对于document.documentElement.parentNode为null.(这里作者说错了,document.documentElement.parentNode 是document, 而document.parentNode是null)
- previousSibling和nextSibling访问节点的左和右的邻居节点。
<!DOCTYPE HTML>
<html>
<head>
<title>My page</title>
</head>
<body>
<div>The header</div>
<ul><li>A list</li></ul>
<div>The footer</div>
</body>
</body>
</html>
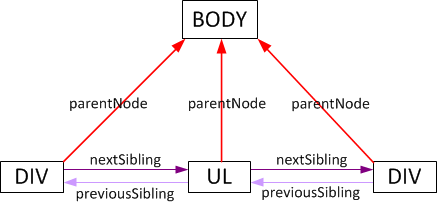
浏览器总是会维护这些属性正确的值,通过这些属性可以修改,添加和删除元素,而不用担心重新赋值给这些属性的问题。
如何判断一个节点是空的?
if (elem.childNodes.length) { ... }
if (elem.firstChild) { ... }
if (elem.lastChild) { ... }
document.body.lastChild.nextSibling总是为null是正确的,因为body的最后一个子节点一定没有右兄弟节点了。document.body.children[0].previousSibling则有可能是null也有可能不是,因为也许body节点的第一个元素的左节点可能是一个text节点。
总结
- 上:parentNode
- 下:children/childNodes, firstChild, lastChild
- 左右:previousSibling/nextSibling
浏览器总是会保证他们的指向是正确值,他们都是只读的,如果他们不存在则为null。
那么怎么遍历整个文档呢?
深度遍历:
function goNodes(node) {
console.log(node.tagName);
if(node.hasChildNodes()) {
for(var i=0;i<node.childNodes.length; i++) {
goNodes(node.childNodes[i]);
}
} else {
return;
}
}
goNodes(document.documentElement);
广度遍历呢?可以思考一下。。。~
function goNodes(node) {
console.log(node.tagName);
var nodesOnSameLevel = [node];
for(var i = 0; i<nodesOnSameLevel.length; i++) {
if(nodesOnSameLevel[i].hasChildNodes()) {
for(var j = 0; j<nodesOnSameLevel[i].children.length; j++){
console.log(nodesOnSameLevel[i].children[j].tagName);
nodesOnSameLevel.push(nodesOnSameLevel[i].children[j]);
}
}
}
}
goNodes(document.documentElement);