AIGC 扫盲贴


本文是 2023 年初学习 AIGC 相关概念的时候写的一些笔记,主要内容来自于腾讯的AIGC发展趋势报告 2023,和阅读报告时对一些技术背景的补充了解。比较适合像我这样的AIGC领域小白扫盲。下面开始具体内容
为什么 AI 能力在 2022 年火了?
总的来看,AIGC 在 2022 年的爆发,主要是得益于深度学习模型方面的技术创新。不断创新的生成算法、预训练模型、多模态等技术融合带来了 AIGC 技术变革,拥有通用性、基础性多模态、参数多、训练数据量大、生成内容高质稳定等特征的 AIGC 模型成为了自动化内容生产的“工厂”和“流水线”。
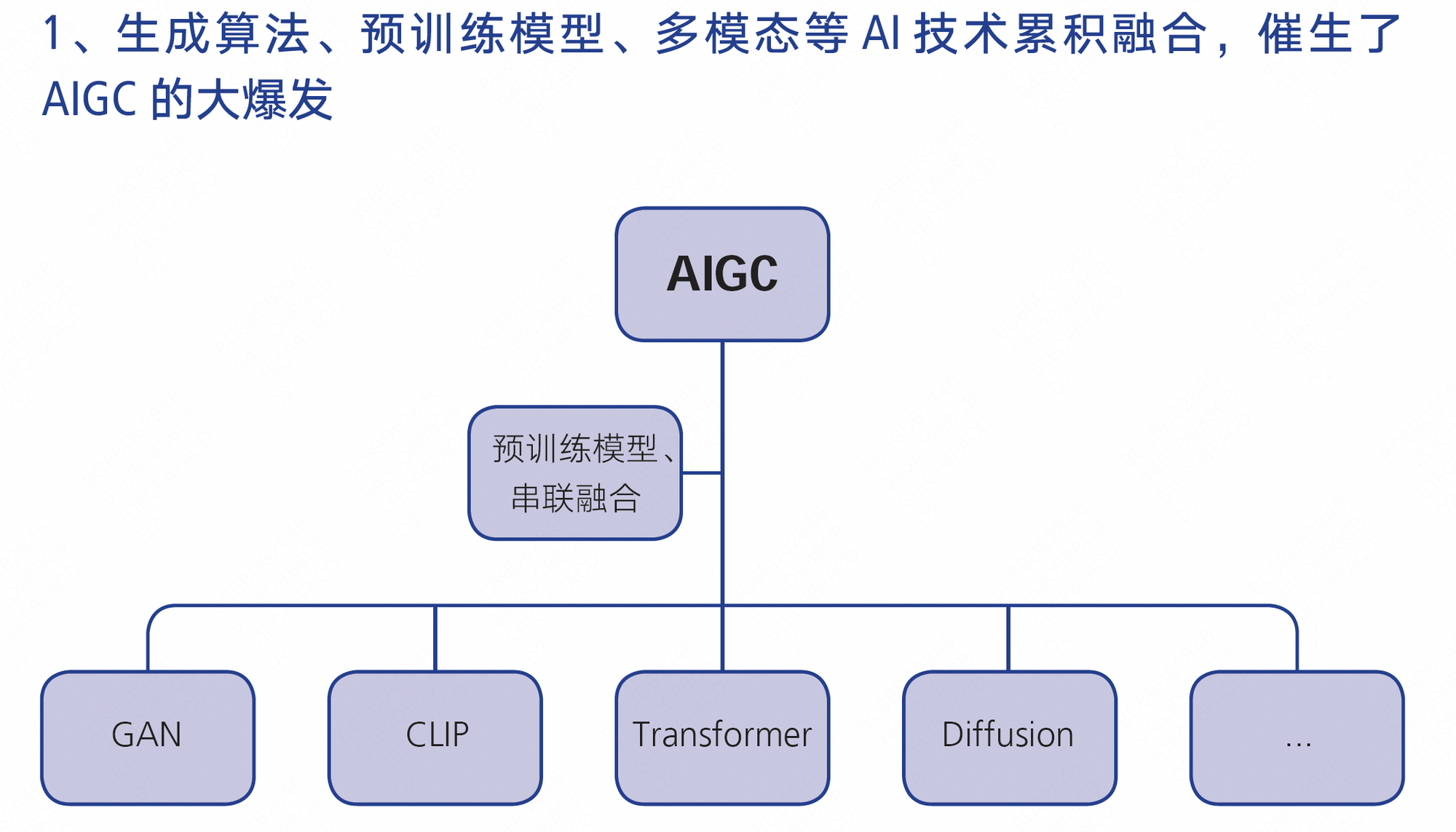
AIGC 是什么?
AIGC(Artifical Intelligence Generated Content),狭义的含义是指利用人工智能自动生成内容,广义上可以看作是像人类一样具备生成创造能力的 AI 技术。国内通常用 AIGC,国外常用 生成式 AI(Generative AI)的表述。
过去的人工智能偏向于分析能力,比如各种个性化推荐算法;而现在人工智能正在生成新的东西,实现了人工智能从理解、感知世界到生成、创造世界的跃迁。
基础概念
生成算法
几种基础的生成算法模型


让 GPT 简单解释一下这几种模型的概念和使用场景:
VAE(VariationalAutoencoders):变分自动编码,基于变分下界约束得到的Encoder-Decoder模型对
Flow-based models:基于流的生成模型,学习一个非线性双射转换 (biiective transformation),其将训练数据映射到另-个空间,在该空间上分布是可以因子化的整个模型架构依靠直接最大化 log-likelihood 来完成
GAN(Generative Adversarial Networks):生成对抗网络,是一种用于生成模型的深度学习算法。GAN由两个神经网络组成,一个生成器和一个判别器。生成器试图生成与真实数据相似的假数据,而判别器则试图区分真实数据和假数据。两个网络相互对抗,最终生成器会生成越来越逼真的假数据。GAN广泛应用于图像、音频、视频等领域的生成任务。
CLIP(Contrastive Language-Image Pre-Training):对比语言-图像预训练模型,是一种用于自然语言处理和计算机视觉的深度学习模型。CLIP使用对比学习的方法,将图像和文本嵌入到同一空间中,使得相似的图像和文本在空间中距离更近。CLIP可以用于图像分类、文本分类、图像检索、文本检索等任务。
Transformer:变形金刚模型,是一种用于自然语言处理的深度学习模型。Transformer使用自注意力机制来处理输入序列,能够捕捉长距离依赖关系。Transformer广泛应用于机器翻译、文本生成、问答系统等领域。BERT、GPT-3、LaMDA 等预训练模型都是基于 Transformer 模型建立的
Diffusion:扩散模型,是一种用于生成模型的深度学习算法。Diffusion通过在噪声上执行随机游走来生成样本,从而避免了需要计算所有可能样本的问题。扩散模型有两个过程,分别为扩散过程和逆扩散过程。在前向扩散阶段对图像逐步施加噪声,直至图像被破坏变成完全的高斯噪声,然后在逆向阶段学习从高斯噪声还原为原始图像的过程。经过训练,该模型可以应用这些去噪方法,从随机输入中合成新的“干净”数据。Diffusion广泛应用于图像、音频、视频等领域的生成任务。
扩散模型相对 GAN 来说具有优势,已经取代 GAN 成为最先进的图像生成器。2021 年6 月 OpenAI 发表论文明确了这个结论和发展趋势。
预训练模型
随着 2018 年谷歌发布基于 Transformer 机器学习方法的自然语言处理预训练模型 BERT,人工智能领域进入了大炼模型参数的预训练模型时代。AI 预训练模型,又称为大模型、基础模型 (foundation model),即基于大量数据(通常使用大规模自我监督学习)训练的、拥有量参数的模型,可以适应广泛的下游任务。这些模型基于迁移学习的思想和深度学习的最新进展,以及大规模应用的计算机系统,展现了令人惊讶的涌现能力,并显著提高各种下游任务的性能。
鉴于这种潜力,预训练模型成为 AI 技术发展的范式变革,许多跨领域的 A 系统将直接建立在预训练模型上。具体到 AIGC 领域,A 预训练模型可以实现多任务、多语言、多方式在各种内容的生成上将扮演关键角色。
按照基本类型分类,预训练模型包括:
(1) 自然语言处理(NLP) 预训练模型,如谷歌的 LaMDA和 PaLM、Open Al的 GPT系列
(2) 计算机视觉(CV) 预训练模型,如微软的 Florence:(3)多模态预训练模型,即融合文字、图片、音视频等多种内容形式
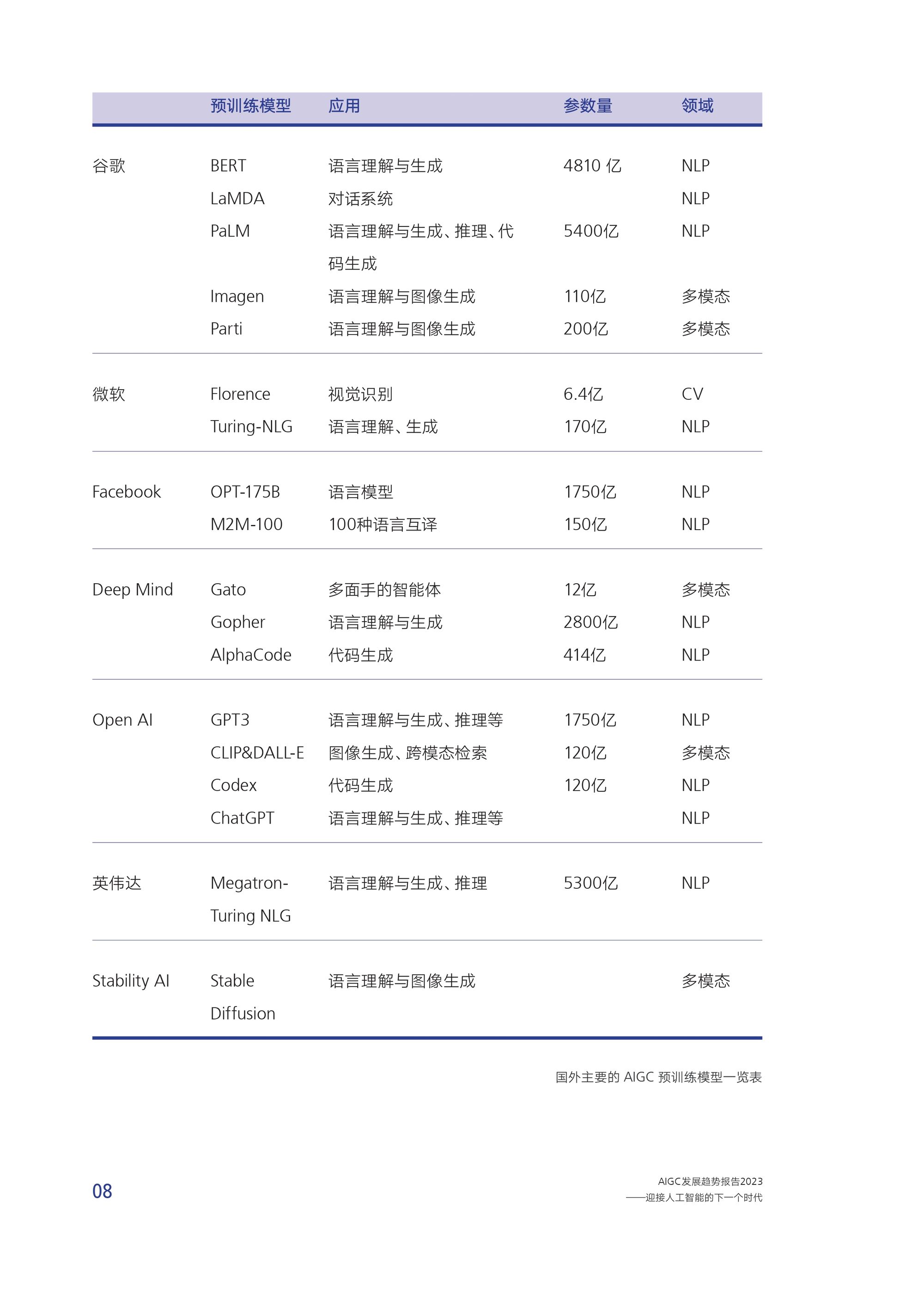
多模态
2021 年 OpenAI 开源跨模态深度学习模型 CLIP(Contrastive Language-Image Pre-Training)。CLIP 模型能够将文字和图像进行关联,并且关联的特征非常丰富。CLIP 模型搜集了网络上超过 40 亿个“文本 - 图像”训练数据,这为后续 AIGC 尤其是输入文本生成图像/视频应用的落地奠定了基础。目前预训练模型已经从早期单一的NLP或CV模型,发展到现在语言文字、图形图像、音视频等多模态、跨模态模型。
CLIP 让文字和图片两个模态找到能够对话的交界点,成为 DALL·E,DALL·E2.0,Stable Diffusion 等突破性 AIGC 成果的基石。
AIGC 消费端
AIGC 应用现状概览:有望塑造数字内容生产与交互新范式,成为未来互联网的内容生成基础设施。
AIGC 在基于自然语言的文本、语音和图片生成领域初步令人满意,特别是知识类中短文,插画等高度风格化的图片创作,创作效果可以与有中级经验的创作者相匹敌;在视频和 3D 等媒介复杂度高的领域处于探索阶段,但成长很快。

3、AIGC 将日益成为未来 3D 互联网的基础支撑
互联网向下一代技术升级和演进的重要方向是从“在线”走向“在场”,迈向 3D 互联网时代AIGC 将成为打造虚实集成世界的基石。AIGC为 3D 互联网带来的价值,既包括 3D 模型、场景、角色制作能效的提升,也能像 Al作画那样,为创作者激发新的灵感。传统的 3D 制作需要耗费大量时间和人力成本。以 2018年发售的游戏《荒野大镖客 2》为例,为了打造约 60 平方公里的虚拟场景、先后有六百余名美术历经 8 年完成。
目前 AIGC 在3D 模型领域还处于探索阶段,从基本原理和使用的模型来看,仍然以扩散模型为基础,基于文字-图片-3D 路径进行处理。谷歌(DreamFusion)和英伟达(Magic3D)在这一领域较为领先,先后在2022 年发布了自己的文字生成 3D 的 AI 模型。1但从生成效果看,距离现在人工制作 3D 容的平均质量还有距离; 生成速度也未能尽如人意。

4、聊天机器人和数字人成为新的、更包容性的用户交互界面,不断拓展应用领域
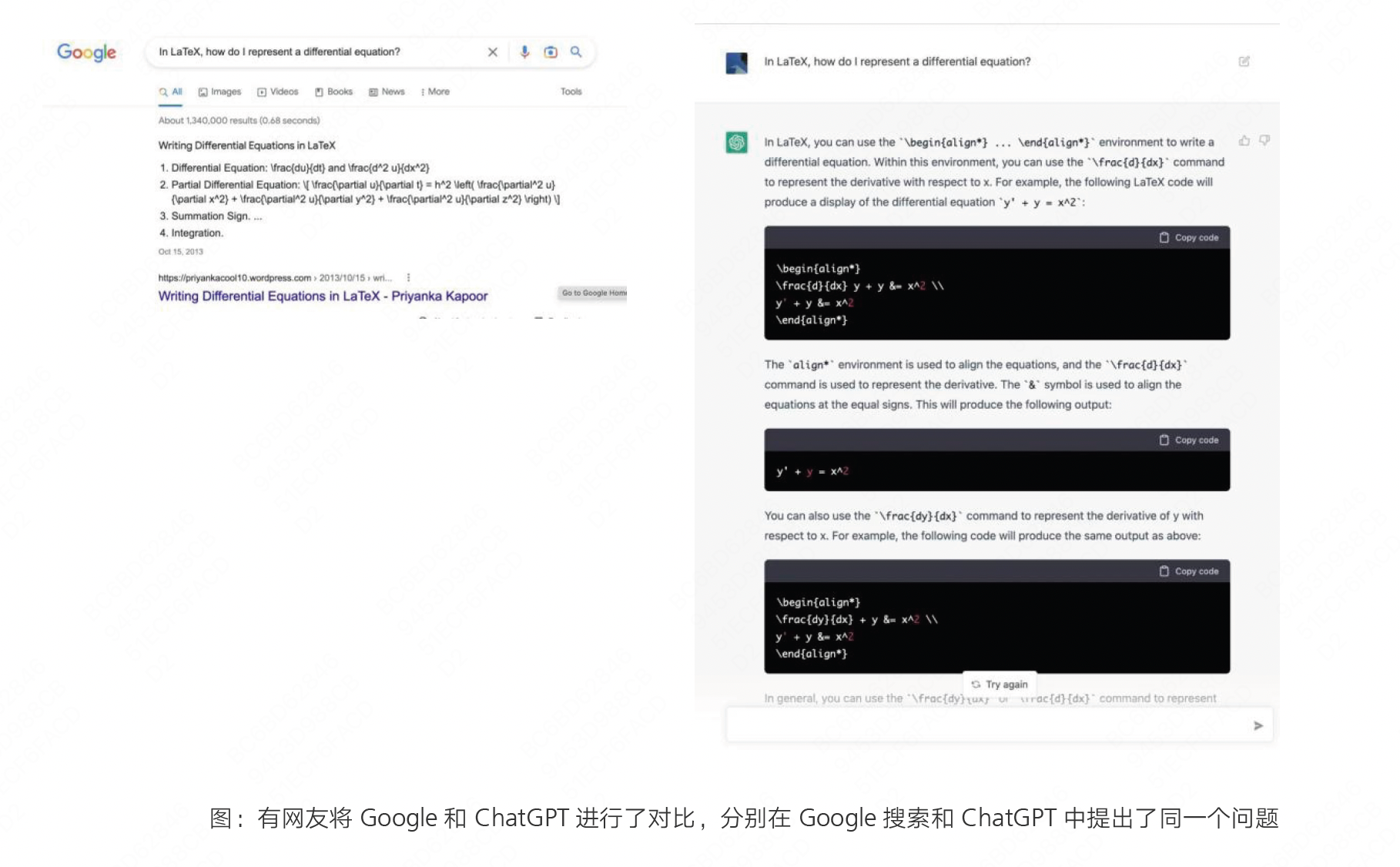
聊天机器人:ChatGPT ,对话式 AIGC,在搜索、知识传播等领域有很大的应用空间。正如Open Al的 CEO Sam Altman 在Twitter 上说过,AIGC 的最终目标是做一个类似于像新时代的搜索引擎。目前的 AIGC 已经可以直面“搜索引擎”产品和“问答社区”。Google 已经为 ChatGPT 带来的威胁发布“红色警报”,着手进行紧急应对。
数字人:
AIGC 发力点:
1) 提升数字人的制作效能。如通过用户上传的照片、视频,通过 AIGC 生成写实类型的数字人。基于 AIGC 的 3D 数字人建模已经初步实现产品化,目前精度可以达到次时代游戏人物级别。如英伟达的 omniverse avatar。
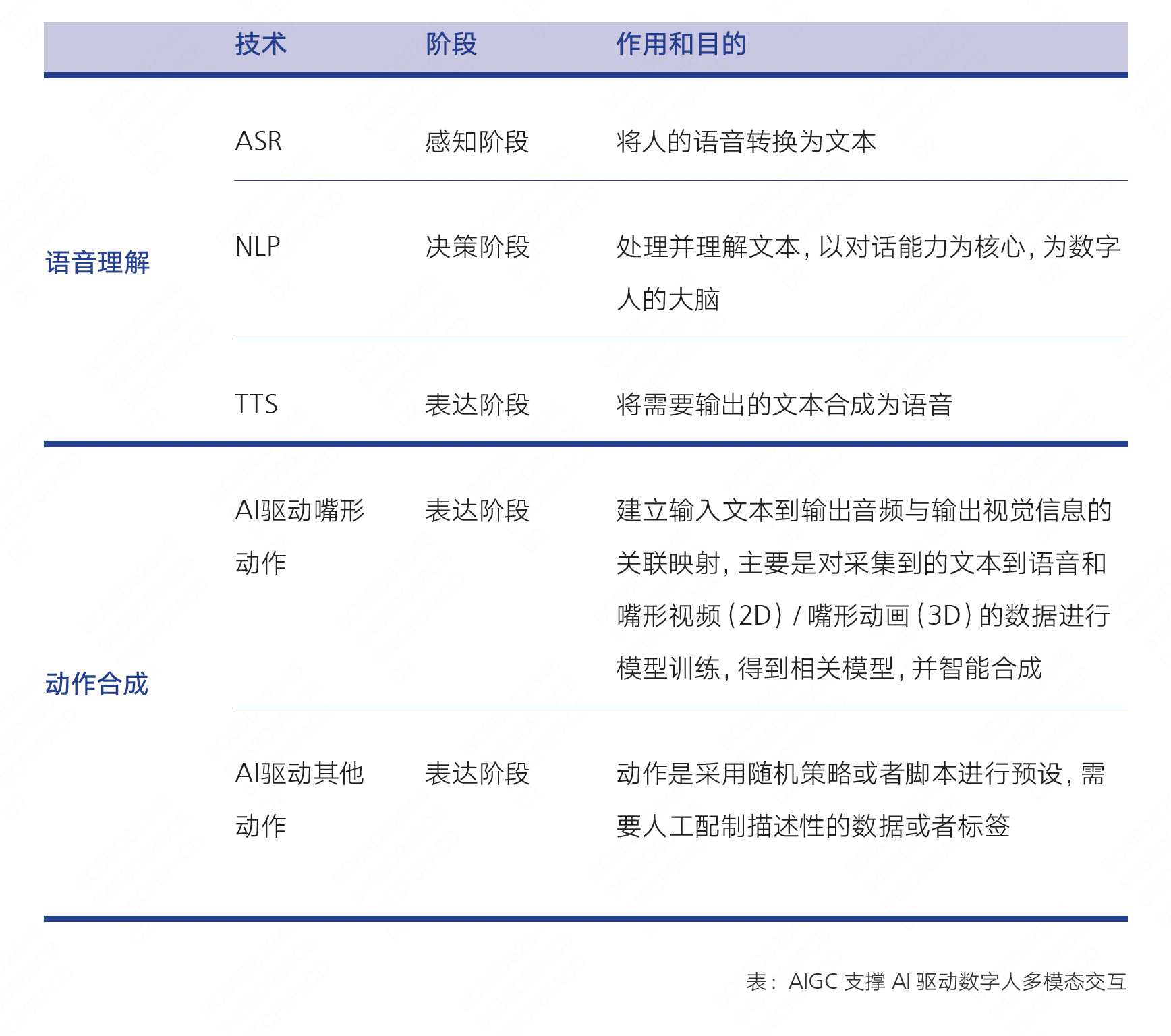
2)AIGC 支撑了 AI 驱动数字人多模态交互中的识别感知和分析决策功能,使其更神似人。
- ASR 是自动语音识别(Automatic Speech Recognition)的缩写,是指将人类语音转换为计算机可识别的文本的技术。
- NLP 是自然语言处理(Natural Language Processing)的缩写,是指计算机处理和理解人类语言的技术,包括文本分析、语音识别、语音合成、机器翻译等。
- TTS 是文本到语音(Text-to-Speech)的缩写,是指将计算机中的文本转换为人类可听的语音的技术。
more todo...
我的疑问❓
大模型会宕机吗?宕机之后会丢失能力/记忆吗?